#conditional SELECT SQL
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
Using CASE Statements for Conditional Logic in SQL Server like IF THEN
In SQL Server, you can use the CASE statement to perform IF…THEN logic within a SELECT statement. The CASE statement evaluates a list of conditions and returns one of multiple possible result expressions. Here’s the basic syntax for using a CASE statement: SELECT column1, column2, CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 ... ELSE default_result END AS…
View On WordPress
#conditional SELECT SQL#dynamic SQL queries#managing SQL data#SQL Server CASE statement#SQL Server tips
0 notes
Text

Wielding Big Data Using PySpark
Introduction to PySpark
PySpark is the Python API for Apache Spark, a distributed computing framework designed to process large-scale data efficiently. It enables parallel data processing across multiple nodes, making it a powerful tool for handling massive datasets.
Why Use PySpark for Big Data?
Scalability: Works across clusters to process petabytes of data.
Speed: Uses in-memory computation to enhance performance.
Flexibility: Supports various data formats and integrates with other big data tools.
Ease of Use: Provides SQL-like querying and DataFrame operations for intuitive data handling.
Setting Up PySpark
To use PySpark, you need to install it and set up a Spark session. Once initialized, Spark allows users to read, process, and analyze large datasets.
Processing Data with PySpark
PySpark can handle different types of data sources such as CSV, JSON, Parquet, and databases. Once data is loaded, users can explore it by checking the schema, summary statistics, and unique values.
Common Data Processing Tasks
Viewing and summarizing datasets.
Handling missing values by dropping or replacing them.
Removing duplicate records.
Filtering, grouping, and sorting data for meaningful insights.
Transforming Data with PySpark
Data can be transformed using SQL-like queries or DataFrame operations. Users can:
Select specific columns for analysis.
Apply conditions to filter out unwanted records.
Group data to find patterns and trends.
Add new calculated columns based on existing data.
Optimizing Performance in PySpark
When working with big data, optimizing performance is crucial. Some strategies include:
Partitioning: Distributing data across multiple partitions for parallel processing.
Caching: Storing intermediate results in memory to speed up repeated computations.
Broadcast Joins: Optimizing joins by broadcasting smaller datasets to all nodes.
Machine Learning with PySpark
PySpark includes MLlib, a machine learning library for big data. It allows users to prepare data, apply machine learning models, and generate predictions. This is useful for tasks such as regression, classification, clustering, and recommendation systems.
Running PySpark on a Cluster
PySpark can run on a single machine or be deployed on a cluster using a distributed computing system like Hadoop YARN. This enables large-scale data processing with improved efficiency.
Conclusion
PySpark provides a powerful platform for handling big data efficiently. With its distributed computing capabilities, it allows users to clean, transform, and analyze large datasets while optimizing performance for scalability.
For Free Tutorials for Programming Languages Visit-https://www.tpointtech.com/
2 notes
·
View notes
Text
SQL injection

we will recall SQLi types once again because examples speak louder than explanations!
In-band SQL Injection
This technique is considered the most common and straightforward type of SQL injection attack. In this technique, the attacker uses the same communication channel for both the injection and the retrieval of data. There are two primary types of in-band SQL injection:
Error-Based SQL Injection: The attacker manipulates the SQL query to produce error messages from the database. These error messages often contain information about the database structure, which can be used to exploit the database further. Example: SELECT * FROM users WHERE id = 1 AND 1=CONVERT(int, (SELECT @@version)). If the database version is returned in the error message, it reveals information about the database.
Union-Based SQL Injection: The attacker uses the UNION SQL operator to combine the results of two or more SELECT statements into a single result, thereby retrieving data from other tables. Example: SELECT name, email FROM users WHERE id = 1 UNION ALL SELECT username, password FROM admin.
Inferential (Blind) SQL Injection
Inferential SQL injection does not transfer data directly through the web application, making exploiting it more challenging. Instead, the attacker sends payloads and observes the application’s behaviour and response times to infer information about the database. There are two primary types of inferential SQL injection:
Boolean-Based Blind SQL Injection: The attacker sends an SQL query to the database, forcing the application to return a different result based on a true or false condition. By analysing the application’s response, the attacker can infer whether the payload was true or false. Example: SELECT * FROM users WHERE id = 1 AND 1=1 (true condition) versus SELECT * FROM users WHERE id = 1 AND 1=2 (false condition). The attacker can infer the result if the page content or behaviour changes based on the condition.
Time-Based Blind SQL Injection: The attacker sends an SQL query to the database, which delays the response for a specified time if the condition is true. By measuring the response time, the attacker can infer whether the condition is true or false. Example: SELECT * FROM users WHERE id = 1; IF (1=1) WAITFOR DELAY '00:00:05'--. If the response is delayed by 5 seconds, the attacker can infer that the condition was true.
Out-of-band SQL Injection
Out-of-band SQL injection is used when the attacker cannot use the same channel to launch the attack and gather results or when the server responses are unstable. This technique relies on the database server making an out-of-band request (e.g., HTTP or DNS) to send the query result to the attacker. HTTP is normally used in out-of-band SQL injection to send the query result to the attacker's server. We will discuss it in detail in this room.
Each type of SQL injection technique has its advantages and challenges.
3 notes
·
View notes
Text
How to Improve Database Performance with Smart Optimization Techniques
Database performance is critical to the efficiency and responsiveness of any data-driven application. As data volumes grow and user expectations rise, ensuring your database runs smoothly becomes a top priority. Whether you're managing an e-commerce platform, financial software, or enterprise systems, sluggish database queries can drastically hinder user experience and business productivity.
In this guide, we’ll explore practical and high-impact strategies to improve database performance, reduce latency, and increase throughput.
1. Optimize Your Queries
Poorly written queries are one of the most common causes of database performance issues. Avoid using SELECT * when you only need specific columns. Analyze query execution plans to understand how data is being retrieved and identify potential inefficiencies.
Use indexed columns in WHERE, JOIN, and ORDER BY clauses to take full advantage of the database indexing system.
2. Index Strategically
Indexes are essential for speeding up data retrieval, but too many indexes can hurt write performance and consume excessive storage. Prioritize indexing on columns used in search conditions and join operations. Regularly review and remove unused or redundant indexes.
3. Implement Connection Pooling
Connection pooling allows multiple application users to share a limited number of database connections. This reduces the overhead of opening and closing connections repeatedly, which can significantly improve performance, especially under heavy load.
4. Cache Frequently Accessed Data
Use caching layers to avoid unnecessary hits to the database. Frequently accessed and rarely changing data—such as configuration settings or product catalogs—can be stored in in-memory caches like Redis or Memcached. This reduces read latency and database load.
5. Partition Large Tables
Partitioning splits a large table into smaller, more manageable pieces without altering the logical structure. This improves performance for queries that target only a subset of the data. Choose partitioning strategies based on date, region, or other logical divisions relevant to your dataset.
6. Monitor and Tune Regularly
Database performance isn’t a one-time fix—it requires continuous monitoring and tuning. Use performance monitoring tools to track query execution times, slow queries, buffer usage, and I/O patterns. Adjust configurations and SQL statements accordingly to align with evolving workloads.
7. Offload Reads with Replication
Use read replicas to distribute query load, especially for read-heavy applications. Replication allows you to spread read operations across multiple servers, freeing up the primary database to focus on write operations and reducing overall latency.
8. Control Concurrency and Locking
Poor concurrency control can lead to lock contention and delays. Ensure your transactions are short and efficient. Use appropriate isolation levels to avoid unnecessary locking, and understand the impact of each level on performance and data integrity.
0 notes
Text
Smart Adaptive Filtering Improves AlloyDB AI Vector Search

A detailed look at AlloyDB's vector search improvements
Intelligent Adaptive Filtering Improves Vector Search Performance in AlloyDB AI
Google Cloud Next 2025: Google Cloud announced new ScaNN index upgrades for AlloyDB AI to improve structured and unstructured data search quality and performance. The Google Cloud Next 2025 advancements meet the increased demand for developers to create generative AI apps and AI agents that explore many data kinds.
Modern relational databases like AlloyDB for PostgreSQL now manage unstructured data with vector search. Combining vector searches with SQL filters on structured data requires careful optimisation for high performance and quality.
Filtered Vector Search issues
Filtered vector search allows specified criteria to refine vector similarity searches. An online store managing a product catalogue with over 100,000 items in an AlloyDB table may need to search for certain items using structured information (like colour or size) and unstructured language descriptors (like “puffer jacket”). Standard queries look like this:
Selected items: * WHERE text_embedding <-> Color=maroon, text-embedding-005, puff jacket, google_ml.embedding LIMIT 100
In the second section, the vector-indexed text_embedding column is vector searched, while the B-tree-indexed colour column is treated to the structured filter color='maroon'.
This query's efficiency depends on the database's vector search and SQL filter sequence. The AlloyDB query planner optimises this ordering based on workload. The filter's selectivity heavily influences this decision. Selectivity measures how often a criterion appears in the dataset.
Optimising with Pre-, Post-, and Inline Filters
AlloyDB's query planner intelligently chooses techniques using filter selectivity:
High Selectivity: The planner often employs a pre-filter when a filter is exceedingly selective, such as 0.2% of items being "maroon." Only a small part of data meets the criterion. After applying the filter (e.g., WHERE color='maroon'), the computationally intensive vector search begins. Using a B-tree index, this shrinks the candidate set from 100,000 to 200 products. Only this smaller set is vector searched (also known as a K-Nearest Neighbours or KNN search), assuring 100% recall in the filtered results.
Low Selectivity: A pre-filter that doesn't narrow the search field (e.g., 90% of products are “blue”) is unsuccessful. Planners use post-filter methods in these cases. First, an Approximate Nearest Neighbours (ANN) vector search using indexes like ScaNN quickly identifies the top 100 candidates based on vector similarity. After retrieving candidates, the filter condition (e.g., WHERE color='blue') is applied. This strategy works effectively for filters with low selectivity because many initial candidates fit the criteria.
Medium Selectivity: AlloyDB provides inline filtering (in-filtering) for filters with medium selectivity (0.5–10%, like “purple”). This method uses vector search and filter criteria. A bitmap from a B-tree index helps AlloyDB find approximate neighbours and candidates that match the filter in one run. Pre-filtering narrows the search field, but post-filtering on a highly selective filter does not produce too few results.
Learn at query time with adaptive filtering
Complex real-world workloads and filter selectivities can change over time, causing the query planner to make inappropriate selectivity decisions based on outdated facts. Poor execution tactics and results may result.
AlloyDB ScaNN solves this using adaptive filtration. This latest update lets AlloyDB use real-time information to determine filter selectivity. This real-time data allows the database to change its execution schedule for better filter and vector search ranking. Adaptive filtering reduces planner miscalculations.
Get Started
These innovations, driven by an intelligent database engine, aim to provide outstanding search results as data evolves.
In preview, adaptive filtering is available. With AlloyDB's ScaNN index, vector search may begin immediately. New Google Cloud users get $300 in free credits and a 30-day AlloyDB trial.
#AdaptiveFiltering#AlloyDBAI#AlloyDBScaNNindex#vectorsearch#AlloyDBAIVectorSearch#AlloyDBqueryplanner#technology#technews#technologynews#news#govindhtech
0 notes
Text
Master SQL in 2025: The Only Bootcamp You’ll Ever Need

When it comes to data, one thing is clear—SQL is still king. From business intelligence to data analysis, web development to mobile apps, Structured Query Language (SQL) is everywhere. It’s the language behind the databases that run apps, websites, and software platforms across the world.
If you’re looking to gain practical skills and build a future-proof career in data, there’s one course that stands above the rest: the 2025 Complete SQL Bootcamp from Zero to Hero in SQL.
Let’s dive into what makes this bootcamp a must for learners at every level.
Why SQL Still Matters in 2025
In an era filled with cutting-edge tools and no-code platforms, SQL remains an essential skill for:
Data Analysts
Backend Developers
Business Intelligence Specialists
Data Scientists
Digital Marketers
Product Managers
Software Engineers
Why? Because SQL is the universal language for interacting with relational databases. Whether you're working with MySQL, PostgreSQL, SQLite, or Microsoft SQL Server, learning SQL opens the door to querying, analyzing, and interpreting data that powers decision-making.
And let’s not forget—it’s one of the highest-paying skills on the job market today.
Who Is This Bootcamp For?
Whether you’re a complete beginner or someone looking to polish your skills, the 2025 Complete SQL Bootcamp from Zero to Hero in SQL is structured to take you through a progressive learning journey. You’ll go from knowing nothing about databases to confidently querying real-world datasets.
This course is perfect for:
✅ Beginners with no prior programming experience ✅ Students preparing for tech interviews ✅ Professionals shifting to data roles ✅ Freelancers and entrepreneurs ✅ Anyone who wants to work with data more effectively
What You’ll Learn: A Roadmap to SQL Mastery
Let’s take a look at some of the key skills and topics covered in this course:
🔹 SQL Fundamentals
What is SQL and why it's important
Understanding databases and tables
Creating and managing database structures
Writing basic SELECT statements
🔹 Filtering & Sorting Data
Using WHERE clauses
Logical operators (AND, OR, NOT)
ORDER BY and LIMIT for controlling output
🔹 Aggregation and Grouping
COUNT, SUM, AVG, MIN, MAX
GROUP BY and HAVING
Combining aggregate functions with filters
🔹 Advanced SQL Techniques
JOINS: INNER, LEFT, RIGHT, FULL
Subqueries and nested SELECTs
Set operations (UNION, INTERSECT)
Case statements and conditional logic
🔹 Data Cleaning and Manipulation
UPDATE, DELETE, and INSERT statements
Handling NULL values
Using built-in functions for data formatting
🔹 Real-World Projects
Practical datasets to work on
Simulated business cases
Query optimization techniques
Hands-On Learning With Real Impact
Many online courses deliver knowledge. Few deliver results.
The 2025 Complete SQL Bootcamp from Zero to Hero in SQL does both. The course is filled with hands-on exercises, quizzes, and real-world projects so you actually apply what you learn. You’ll use modern tools like PostgreSQL and pgAdmin to get your hands dirty with real data.
Why This Course Stands Out
There’s no shortage of SQL tutorials out there. But this bootcamp stands out for a few big reasons:
✅ Beginner-Friendly Structure
No coding experience? No problem. The course takes a gentle approach to build your confidence with simple, clear instructions.
✅ Practice-Driven Learning
Learning by doing is at the heart of this course. You’ll write real queries, not just watch someone else do it.
✅ Lifetime Access
Revisit modules anytime you want. Perfect for refreshing your memory before an interview or brushing up on a specific concept.
✅ Constant Updates
SQL evolves. This bootcamp evolves with it—keeping you in sync with current industry standards in 2025.
✅ Community and Support
You won’t be learning alone. With a thriving student community and Q&A forums, support is just a click away.
Career Opportunities After Learning SQL
Mastering SQL can open the door to a wide range of job opportunities. Here are just a few roles you’ll be prepared for:
Data Analyst: Analyze business data and generate insights
Database Administrator: Manage and optimize data infrastructure
Business Intelligence Developer: Build dashboards and reports
Full Stack Developer: Integrate SQL with web and app projects
Digital Marketer: Track user behavior and campaign performance
In fact, companies like Amazon, Google, Netflix, and Facebook all require SQL proficiency in many of their job roles.
And yes—freelancers and solopreneurs can use SQL to analyze marketing campaigns, customer feedback, sales funnels, and more.
Real Testimonials From Learners
Here’s what past students are saying about this bootcamp:
⭐⭐⭐⭐⭐ “I had no experience with SQL before taking this course. Now I’m using it daily at my new job as a data analyst. Worth every minute!” – Sarah L.
⭐⭐⭐⭐⭐ “This course is structured so well. It’s fun, clear, and packed with challenges. I even built my own analytics dashboard!” – Jason D.
⭐⭐⭐⭐⭐ “The best SQL course I’ve found on the internet—and I’ve tried a few. I was up and running with real queries in just a few hours.” – Meera P.
How to Get Started
You don’t need to enroll in a university or pay thousands for a bootcamp. You can get started today with the 2025 Complete SQL Bootcamp from Zero to Hero in SQL and build real skills that make you employable.
Just grab a laptop, follow the course roadmap, and dive into your first database. No fluff. Just real, useful skills.
Tips to Succeed in the SQL Bootcamp
Want to get the most out of your SQL journey? Keep these pro tips in mind:
Practice regularly: SQL is a muscle—use it or lose it.
Do the projects: Apply what you learn to real datasets.
Take notes: Summarize concepts in your own words.
Explore further: Try joining Kaggle or GitHub to explore open datasets.
Ask questions: Engage in course forums or communities for deeper understanding.
Your Future in Data Starts Now
SQL is more than just a skill. It’s a career-launching power tool. With this knowledge, you can transition into tech, level up in your current role, or even start your freelance data business.
And it all begins with one powerful course: 👉 2025 Complete SQL Bootcamp from Zero to Hero in SQL
So, what are you waiting for?
Open the door to endless opportunities and unlock the world of data.
0 notes
Text
How do I get prepared for TCS technical interview questions?
Cracking the TCS Technical Interview – Here's How to Prepare
If you're getting ready for TCS placements, the first thing you need to understand is the TCS recruitment process. TCS mostly hires through the TCS NQT (National Qualifier Test), and the selection happens in multiple stages.
TCS Recruitment Process
Online Assessment (TCS NQT) This is the first step, where you’ll be tested across several sections:
Numerical Ability – Covers basic math topics like percentages, profit and loss, time and work, etc.
Verbal Ability – Includes English grammar, reading comprehension, sentence correction, and vocabulary.
Reasoning Ability – Focuses on puzzles, sequences, and logical thinking.
Programming Logic – Basic programming concepts such as loops, functions, and conditionals.
Coding Round – You’ll be asked to solve coding problems using C, C++, Java, or Python.
Technical Interview Once you clear the online assessment, you'll move on to the technical interview. This round includes questions on:
Programming languages like C, C++, Java, or Python
Data Structures and Algorithms – Arrays, Linked Lists, Searching, Sorting, and more
Object-Oriented Programming – Classes, Inheritance, Polymorphism, and other core concepts
Database Management – SQL queries, normalization, joins, and other DBMS topics
Managerial and HR Interview These final rounds evaluate your communication skills, attitude, problem-solving approach, and ability to work in a team. You may also be asked about your final year project and previous experiences.
How to Prepare for TCS Interviews
Start with the basics – make sure your programming fundamentals are clear.
Practice coding questions every day to strengthen your logic and problem-solving skills.
Refer to our blog on TCS NQT Coding Questions and Answers 2025 for real practice problems.
If you're aiming for a higher package, check out the TCS NQT Advanced Coding Questions as well.
Prepare well for your final year project – interviewers often ask detailed questions about it.
Taking mock interviews and practice tests can help you gain confidence and improve your performance.
For complete resources, including sample papers and the latest updates, visit our TCS Dashboard here: TCS Dashboard – PrepInsta
Start preparing the smart way and increase your chances of landing the job.
1 note
·
View note
Text
Get Started Coding for non-programmers

How to Get Started with Coding: A Guide for Non-Techies
If you ever considered learning how to Get Started Coding for non-programmers but were intimidated by technical terms or daunted by the prospect, you're in good company. The good news is that coding isn't for "techies" alone. Anyone can learn to code, no matter their background or experience. In this guide, we'll take you through the fundamentals of how to get started coding, whether you're looking to create a website, work with data, or simply learn how the technology that surrounds you operates. Why Learn to Code? Before diving into the "how," it's worth knowing the "why." Coding can unlock new doors, both personally and professionally. Some of the reasons why learning to code is worth it include: Problem-solving abilities: Programming allows you to dissect difficult problems and identify solutions. Career adaptability: More and more careers, from marketing to medicine, are turning to coding as a requirement. Empowerment: Code knowledge enables you to have a better understanding of the technology you're using daily and enables you to own your own project development. Creativity: Coding isn't purely logical—it's also about making new things and creating your own ideas. Step 1: Choose Your Learning Path Before you start, consider what you are most interested in. The route you take will depend on what you want to do. These are some of the most popular routes: Web Development: Creating websites and web apps (learn HTML, CSS, JavaScript). Data Science: Examining data, visualizing patterns, and making informed decisions based on data (learn Python, R, or SQL). App Development: Creating mobile apps for iOS or Android (learn Swift or Kotlin). Game Development: Building video games (learn Unity or Unreal Engine using C# or C++). Take a moment to determine which area speaks to you. Don't stress about choosing the "perfect" path—coding skills are interchangeable, and you can always make a change later. Step 2: Begin with the Basics After you've decided on your route, it's time to begin learning. As a novice, you'll want to begin with the fundamentals of coding. Here are some fundamental concepts to familiarize yourself with: Variables: A means of storing data (such as numbers or text). Data Types: Familiarity with various types of data, including integers, strings (text), and booleans (true/false). Loops: Doing things over and over again without writing the same code over and over. Conditionals: Deciding things in code using if-else statements. Functions: These are the Building blocks of code that can be reused to accomplish particular tasks. For instance, when you're learning Python, you could begin with a basic program such as: Step 3: Select the Proper Learning Material There's plenty of learning material out there for beginners, and the correct resource can mean a big difference in how rapidly you learn to code. Some of the most popular methods include: Online Courses: Websites such as Coursera, Udemy, edX, and freeCodeCamp provide sequential courses, and some of these are available free of charge. Interactive Platforms: Sites such as Codecademy, Khan Academy, or LeetCode offer in-the-code lessons that walk you through problems sequentially. Books: There are a lot of code books for beginners, such as "Python Crash Course" or "Automate the Boring Stuff with Python." YouTube Tutorials: YouTube contains a plethora of coding tutorials for beginners where you can work through actual projects. For complete beginners, sites such as freeCodeCamp and Codecademy are excellent as they enable you to code in the browser itself, so you don't have to install anything. Step 4: Practice, Practice, Practice The secret to mastering coding is regular practice. Similar to learning a musical instrument or a foreign language, you'll have to develop muscle memory and confidence. Practice Coding Challenges: Sites such as HackerRank or Codewars offer exercises that allow you to practice what you've learned. Build Small Projects: Begin with small projects, like a to-do list, a basic calculator, or a personal blog. This reinforces your learning and makes coding more rewarding. Join Coding Communities: Sites like GitHub, Stack Overflow, or Reddit's /r/learnprogramming are excellent for asking questions, sharing your work, and receiving feedback. Step 5: Don't Be Afraid to Make Mistakes Keep in mind that errors are all part of learning. While you're coding, you'll get errors, and that's completely fine. Debugging is a skill that takes time to master. The more you code, the more accustomed you'll get to spotting and resolving errors in your code. Here's a useful approach when faced with errors: Read the error message: It usually indicates precisely what's wrong. Search online: Chances are, someone else has faced the same issue. Platforms like Stack Overflow are full of solutions. Break the problem down: If something’s not working, try to isolate the issue and test each part of your code step by step. Step 6: Stay Motivated Get Started Coding for Non-Programmers. Learning to code can be challenging, especially in the beginning. Here are a few tips to stay motivated: Break goals into bite-sized pieces: Don't try to learn it all at once; set mini goals such as "Complete this course" or "Finish this project." Pat yourself on the back: Celebrate every time you complete a project or figure out a problem. Get a learning buddy: It's always more fun and engaging with someone learning alongside you. Don't do it in one sitting: It takes time to learn to code. Relax, be good to yourself, and enjoy the process. Conclusion Learning to Get Started Coding for non-programmers might seem daunting, but it’s possible with the right mindset and resources. Start small, be consistent, and remember that every coder, no matter how experienced, was once a beginner. By following these steps—choosing the right learning path, mastering the basics, practicing regularly, and staying motivated—you’ll soon gain the skills and confidence you need to code like a pro. Read the full article
0 notes
Text
SQL Tutorial for Beginners: Learn How to Query Databases
In today’s data-driven world, almost every application, website, or business process involves data in some form. From your favorite e-commerce platform to your personal banking app, data is stored, managed, and retrieved using databases. To interact with these databases, we use a powerful language called SQL.
If you’re a beginner looking to learn how to query databases, you’re in the right place. This SQL tutorial will introduce you to the basics of SQL (Structured Query Language) and explain how you can use it to communicate with databases—no programming experience required.

What is SQL?
SQL stands for Structured Query Language. It’s the standard language used to store, retrieve, manage, and manipulate data in relational databases—databases that store data in tables, much like spreadsheets.
Think of a relational database as a collection of tables, where each table contains rows and columns. Each column has a specific type of data, like names, dates, or prices, and each row is a record (an entry) in the table.
Why Learn SQL?
SQL is one of the most in-demand skills for developers, data analysts, data scientists, and even marketers and business professionals. Here’s why learning SQL is a great idea:
Universal: It’s used by nearly every industry that deals with data.
Easy to Learn: SQL has a relatively simple and readable syntax.
Powerful: SQL allows you to ask complex questions and get exactly the data you need.
Great for Career Growth: SQL knowledge is a key skill in many tech and data-focused roles.
Core Concepts You Need to Know
Before jumping into actual queries, it’s helpful to understand some key concepts and terminology:
1. Tables
A table is a collection of data organized in rows and columns. For example, a Customers table might include columns like CustomerID, Name, Email, and Phone.
2. Rows
Each row in a table is a record. For example, one row in the Customers table could represent a single person.
3. Columns
Each column represents a specific attribute of the data. In our example, Email is a column that stores email addresses of customers.
4. Queries
A query is a question you ask the database. You use SQL to write queries and tell the database what information you want to retrieve.
Basic SQL Commands for Beginners
Here are the most commonly used SQL statements that beginners should become familiar with:
1. SELECT
The SELECT statement is used to read or retrieve data from a table. It’s the most commonly used SQL command.
Example (in simple English): "Show me all the data in the Customers table."
2. WHERE
The WHERE clause helps you filter results based on specific conditions.
Example: "Show me all customers whose country is Canada."
3. ORDER BY
You can sort the data using the ORDER BY clause.
Example: "Show customers sorted by their names in alphabetical order."
4. INSERT INTO
This command adds new records (rows) to a table.
Example: "Add a new customer named Alice with her email and phone number."
5. UPDATE
This modifies existing records in a table.
Example: "Change the phone number of customer with ID 10."
6. DELETE
This removes records from a table.
Example: "Delete the customer with ID 15."
A Real-Life Example: Online Store
Imagine you run an online store, and you have a table called Products. This table includes columns like ProductID, Name, Category, and Price.
With SQL, you could:
Find all products in the “Electronics” category.
List the top 5 most expensive products.
Update the price of a specific product.
Remove discontinued items.
SQL allows you to manage all of this with a few clear instructions.
How to Practice SQL
Learning SQL is best done by doing. Fortunately, there are many free and interactive tools you can use to practice writing SQL queries without needing to install anything:
Tpoint Tech (tpointtech.com/sql-tutorial)
W3Schools SQL Tutorial (w3schools.com/sql)
LeetCode SQL problems (great for more advanced practice)
Mode SQL Tutorial (mode.com/sql-tutorial)
These platforms let you write and test queries directly in your browser, often with real-world examples.
Final Thoughts
SQL is a foundational tool for anyone working with data. Whether you're a developer managing back-end systems, a data analyst exploring customer trends, or a marketer analyzing campaign results, knowing how to query databases will empower you to make smarter, data-driven decisions.
This beginner-friendly tutorial is just the first step. As you become more comfortable with SQL, you'll be able to write more complex queries, join multiple tables, and dive into advanced topics like subqueries and database design.
0 notes
Text
Combining Azure Data Factory with Azure Event Grid for Event-Driven Workflows

Traditional data pipelines often run on schedules — every 15 minutes, every hour, etc. But in a real-time world, that isn’t always enough. When latency matters, event-driven architectures offer a more agile solution.
Enter Azure Data Factory (ADF) + Azure Event Grid — a powerful duo for building event-driven data workflows that react to file uploads, service messages, or data changes instantly.
Let’s explore how to combine them to build more responsive, efficient, and scalable pipelines.
⚡ What is Azure Event Grid?
Azure Event Grid is a fully managed event routing service that enables your applications to react to events in near real-time. It supports:
Multiple event sources: Azure Blob Storage, Event Hubs, IoT Hub, custom apps
Multiple event handlers: Azure Functions, Logic Apps, WebHooks, and yes — Azure Data Factory
🎯 Why Use Event Grid with Azure Data Factory?
BenefitDescription🕒 Real-Time TriggersTrigger ADF pipelines the moment a file lands in Blob Storage — no polling needed🔗 Decoupled ArchitectureKeep data producers and consumers independent⚙️ Flexible RoutingRoute events to different pipelines, services, or queues based on metadata💰 Cost-EffectivePay only for events received — no need for frequent pipeline polling
🧱 Core Architecture Pattern
Here’s how the integration typically looks:pgsqlData Source (e.g., file uploaded to Blob Storage) ↓ Event Grid ↓ ADF Webhook Trigger (via Logic App or Azure Function) ↓ ADF Pipeline runs to ingest/transform data
🛠 Step-by-Step: Setting Up Event-Driven Pipelines
✅ 1. Enable Event Grid on Blob Storage
Go to your Blob Storage account
Navigate to Events > + Event Subscription
Select Event Type: Blob Created
Choose the endpoint — typically a Logic App, Azure Function, or Webhook
✅ 2. Create a Logic App to Trigger ADF Pipeline
Use Logic Apps if you want simple, no-code integration:
Use the “When a resource event occurs” Event Grid trigger
Add an action: “Create Pipeline Run (Azure Data Factory)”
Pass required parameters (e.g., file name, path) from the event payload
🔁 You can pass the blob path into a dynamic dataset in ADF for ingestion or transformation.
✅ 3. (Optional) Add Routing Logic
Use conditional steps in Logic Apps or Functions to:
Trigger different pipelines based on file type
Filter based on folder path, metadata, or event source
📘 Use Case Examples
📁 1. File Drop in Data Lake
Event Grid listens to Blob Created
Logic App triggers ADF pipeline to process the new file
🧾 2. New Invoice Arrives via API
Custom app emits event to Event Grid
Azure Function triggers ADF pipeline to pull invoice data into SQL
📈 3. Stream Processing with Event Hubs
Event Grid routes Event Hub messages to ADF or Logic Apps
Aggregated results land in Azure Synapse
🔐 Security and Best Practices
Use Managed Identity for authentication between Logic Apps and ADF
Use Event Grid filtering to avoid noisy triggers
Add dead-lettering to Event Grid for failed deliveries
Monitor Logic App + ADF pipeline failures with Azure Monitor Alerts
🧠 Wrapping Up
Event-driven architectures are key for responsive data systems. By combining Azure Event Grid with Azure Data Factory, you unlock the ability to trigger pipelines instantly based on real-world events — reducing latency, decoupling your system, and improving efficiency.
Whether you’re reacting to file uploads, streaming messages, or custom app signals, this integration gives your pipelines the agility they need.
Want an infographic to go with this blog? I can generate one in your preferred visual style.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Unlock the Power of Data: SQL - Your Essential First Step in Data Science

So, you're eager to dive into the fascinating world of data science? You've heard about Python, R, and complex machine learning algorithms. But before you get swept away by the advanced stuff, let's talk about a foundational skill that's often underestimated but absolutely crucial: SQL (Structured Query Language).
Think of SQL as the universal language for talking to databases – the digital warehouses where most of the world's data resides. Whether you're aiming to analyze customer behavior, predict market trends, or build intelligent applications, chances are you'll need to extract, manipulate, and understand data stored in databases. And that's where SQL shines.
Why SQL is Your Best Friend as a Beginner Data Scientist:
You might be wondering, "With all the fancy tools out there, why bother with SQL?" Here's why it's the perfect starting point for your data science journey:
Ubiquitous and Essential: SQL is the standard language for interacting with relational databases, which are still the backbone of many organizations' data infrastructure. You'll encounter SQL in almost every data science role.
Mastering Data Wrangling: Before you can build models or create visualizations, you need to clean, filter, and transform your data. SQL provides powerful tools for these crucial data wrangling tasks. You can select specific columns, filter rows based on conditions, handle missing values, and join data from multiple tables – all with simple, declarative queries.
Understanding Data Structure: Writing SQL queries forces you to understand how data is organized within databases. This fundamental understanding is invaluable when you move on to more complex analysis and modeling.
Building a Strong Foundation: Learning SQL provides a solid logical and analytical foundation that will make it easier to grasp more advanced data science concepts and tools later on.
Efficiency and Performance: For many data extraction and transformation tasks, SQL can be significantly faster and more efficient than manipulating large datasets in memory with programming languages.
Bridging the Gap: SQL often acts as a bridge between data engineers who manage the databases and data scientists who analyze the data. Being proficient in SQL facilitates better communication and collaboration.
Interview Essential: In almost every data science interview, you'll be tested on your SQL abilities. Mastering it early on gives you a significant advantage.
What You'll Learn with SQL (The Beginner's Toolkit):
As a beginner, you'll focus on the core SQL commands that will empower you to work with data effectively:
SELECT: Retrieve specific columns from a table.
FROM: Specify the table you want to query.
WHERE: Filter rows based on specific conditions.
ORDER BY: Sort the results based on one or more columns.
LIMIT: Restrict the number of rows returned.
JOIN: Combine data from multiple related tables (INNER JOIN, LEFT JOIN, RIGHT JOIN).
GROUP BY: Group rows with the same values in specified columns.
Aggregate Functions: Calculate summary statistics (COUNT, SUM, AVG, MIN, MAX).
Basic Data Manipulation: Learn to insert, update, and delete data (though as a data scientist, you'll primarily focus on querying).
Taking Your First Steps with Xaltius Academy's Data Science and AI Program:
Ready to unlock the power of SQL and build a strong foundation for your data science journey? Xaltius Academy's Data Science and AI program recognizes the critical importance of SQL and integrates it as a fundamental component of its curriculum.
Here's how our program helps you master SQL:
Dedicated Modules: We provide focused modules that systematically introduce you to SQL concepts and commands, starting from the very basics.
Hands-on Practice: You'll get ample opportunities to write and execute SQL queries on real-world datasets through practical exercises and projects.
Real-World Relevance: Our curriculum emphasizes how SQL is used in conjunction with other data science tools and techniques to solve actual business problems.
Expert Guidance: Learn from experienced instructors who can provide clear explanations and answer your questions.
Integrated Skill Development: You'll learn how SQL complements other essential data science skills like Python programming and data visualization.
Conclusion:
Don't let the initial buzz around advanced algorithms overshadow the fundamental importance of SQL. It's the bedrock of data manipulation and a crucial skill for any aspiring data scientist. By mastering SQL, you'll gain the ability to access, understand, and prepare data – the very fuel that drives insightful analysis and powerful AI models. Start your data science journey on solid ground with SQL, and let Xaltius Academy's Data Science and AI program guide you every step of the way. Your data-driven future starts here!
0 notes
Text
Top Skills You Need to Land an Entry-Level Data Analyst Job in India
With businesses increasingly relying on data to drive decision-making, the role of a data analyst has become crucial in various industries. From finance and healthcare to e-commerce and IT, companies are actively hiring data analysts to interpret complex datasets and provide actionable insights. However, breaking into this field requires a strong skill set that aligns with industry expectations. Whether you are a recent graduate or transitioning from another field, mastering the right skills will significantly enhance your employability. This blog explores the essential skills you need to secure an entry-level data analyst job in India from the best Data Analytics Online Training.

1. Proficiency in Microsoft Excel
Excel remains one of the most widely used tools in data analytics. Employers expect candidates to be proficient in using Excel functions such as VLOOKUP, INDEX-MATCH, PivotTables, and conditional formatting. Understanding data cleaning, filtering, and basic statistical analysis in Excel is essential for handling structured data. Advanced Excel skills, including macros and VBA, can further improve your efficiency as an analyst.
2. SQL for Data Manipulation
SQL (Structured Query Language) is a fundamental skill for data analysts, as most companies store data in relational databases. Proficiency in writing SQL queries to retrieve, filter, and manipulate data is essential. You should be comfortable using commands like SELECT, JOIN, GROUP BY, and WHERE to extract meaningful insights from datasets. Additionally, knowledge of database management systems such as MySQL, PostgreSQL, or Microsoft SQL Server is valuable. If you want to learn more about Data Analytics, consider enrolling in an Best Online Training & Placement programs . They often offer certifications, mentorship, and job placement opportunities to support your learning journey.
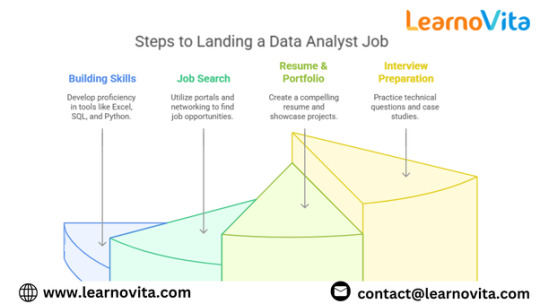
3. Python or R for Data Analysis
While Excel and SQL are important, programming languages like Python and R add significant value to your skill set. Python, with libraries such as Pandas, NumPy, and Matplotlib, is widely used for data analysis, automation, and visualization. R is also preferred in statistical analysis and research-oriented industries. Learning how to clean, manipulate, and visualize data using these languages will help you work with large datasets efficiently.
4. Data Visualization with Tableau and Power BI
Data analysts must present insights in an easy-to-understand manner. Visualization tools like Tableau and Power BI allow you to create interactive dashboards and reports. Employers expect analysts to be proficient in using charts, graphs, and dashboards to communicate trends and business insights effectively. Knowing when to use different visualization techniques enhances decision-making for stakeholders.
5. Understanding of Statistics and Data Interpretation
A solid understanding of statistics is crucial for drawing meaningful conclusions from data. Key statistical concepts such as probability, regression analysis, hypothesis testing, and correlation are frequently applied in data analysis. These concepts help analysts interpret trends, make predictions, and validate business hypotheses.
6. Business Acumen and Problem-Solving Skills
A successful data analyst goes beyond numbers and understands the business context. Business acumen helps you identify key performance indicators (KPIs) relevant to your industry and interpret data to drive business decisions. Employers seek candidates who can analyze data from a strategic perspective and provide actionable insights to improve efficiency and revenue.
7. Communication and Storytelling with Data
Interpreting data is one thing, but effectively communicating insights is equally important. Data analysts must present findings in a way that non-technical stakeholders can understand. Strong storytelling skills, combined with visualization techniques, help convey complex data in a simple and compelling manner.
8. Knowledge of ETL and Data Cleaning
Most raw data is messy and requires cleaning before analysis. Understanding Extract, Transform, Load (ETL) processes and data wrangling techniques is essential. Experience with tools like Alteryx, Talend, or Python libraries like Pandas can help automate data cleaning tasks, making data more structured and reliable for analysis.
Conclusion
Securing an entry-level data analyst job in India requires a well-rounded skill set that includes technical expertise, business acumen, and strong communication abilities. Mastering Excel, SQL, Python, and data visualization tools, along with a solid understanding of statistics and problem-solving, will position you as a strong candidate in the job market. Continuous learning and hands-on practice with real-world datasets will further enhance your employability and help you build a successful career in data analytics.
0 notes
Text
5 Types of SQL Commands You Must Know

It is very important for a user embedded with SQL in database management to have a full-fledged interaction with the database so that the actual work gets done smoothly. Knowing the 5 Types of SQL Commands You Must Know ensures effective data handling, whether you are an amateur developer or an expert. TCCI-Tririd Computer Coaching Institute is one of the leading institutes where expert training and guidance are provided in SQL and Database Management.
These are the five types of SQL commands that one needs to know:
1. Data Definition Language (DDL)- Definition of Database Structure
DDL commands are concerned with defining and changing the structure of the database. Applying these commands has a direct impact on the schema of a database.
CREATE - Used to create tables, databases, index, or views.
ALTER - Modification of an existing database object, which may include the addition of new columns to a table.
DROP- Deletes tables, databases, or other database objects permanently.
TRUNCATE- Deletes all records from a table but keeps the structure for future use.
2. Data Manipulation Language (DML)- Manipulating Data
DML commands allow users to act on the data stored in a database. Retrieval and modification of the data are the primary operations performed by these commands.
INSERT - Inserts new records into a table.
UPDATE - Updates existing records in a table.
DELETE - Deletes a few records from a table.
3. Data Query Language (DQL)- Retrieving Data
The main purpose of DQL is to fetch data from the database.
SELECT - Feeds data from one or many tables based on the stipulated conditions.
4. Data Control Language (DCL)- Controlling Access To Data
DCL commands are meant for the control of users accessing the database.
GRANT - A specific privilege is assigned to users or roles.
REVOKE - Removes previously granted privileges.
5. Transaction Control Language (TCL)- Controlling Transaction
TCL commands are used for the efficient and secure execution of database transactions.
COMMIT- Saves all transaction changes.
ROLLBACK- Undo changes if an error occurs.
SAVEPOINT- Creates intermediate points in a transaction.
Conclusion
If you are someone looking to work with databases, then mastering these five sorts of SQL commands is necessary. To help you understand database management comprehensively, TCCI-Tririd Computer Coaching Institute offers an elaborative SQL training program. Our well-trained instructors guide both beginners and advanced students through practical and real-life applications.
Location: Bopal & Iskon-Ambli Ahmedabad, Gujarat
Call now on +91 9825618292
Get information from: https://tccicomputercoaching.wordpress.com/
FAQs
1. Which is the most important SQL command?
The most important command is SELECT, which helps retrieve data from the database.
2. What are the differences between DDL and DML?
DDL defines the structure of the database, while DML performs actual manipulations and management over data.
3. Can one learn SQL without prior programming experience?
Yes, SQL is easy to learn without coding experience.
4. Why are TCL commands important in SQL?
TCL guarantees that database transactions are carried out well, maintaining the consistency of the data.
Where can I learn SQL professionally? Join TCCI-Tririd Computer Coaching Institute to get expert guidance and hands-on SQL training.
Get started with SQL today and enhance your database management skills with TCCI! 🚀
0 notes
Text
SQL for Data Science: Essential Queries Every Analyst Should Know
Introduction
SQL (Structured Query Language) is the backbone of data science and analytics. It enables analysts to retrieve, manipulate, and analyze large datasets efficiently. Whether you are a beginner or an experienced data professional, mastering SQL queries is essential for data-driven decision-making. In this blog, we will explore the most important SQL queries every data analyst should know.
1. Retrieving Data with SELECT Statement
The SELECT statement is the most basic yet crucial SQL query. It allows analysts to fetch data from a database.
Example:
SELECT name, age, salary FROM employees;
This query retrieves the name, age, and salary of all employees from the employees table.
2. Filtering Data with WHERE Clause
The WHERE clause is used to filter records based on specific conditions.
Example:
SELECT * FROM sales WHERE amount > 5000;
This query retrieves all sales transactions where the amount is greater than 5000.
3. Summarizing Data with GROUP BY & Aggregate Functions
GROUP BY is used with aggregate functions (SUM, COUNT, AVG, MAX, MIN) to group data.
Example:
SELECT department, AVG(salary) FROM employees GROUP BY department;
This query calculates the average salary for each department.
4. Combining Data with JOINs
SQL JOIN statements are used to combine rows from two or more tables based on a related column.
Example:
SELECT employees.name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.id;
This query retrieves employee names along with their department names.
5. Sorting Data with ORDER BY
The ORDER BY clause sorts data in ascending or descending order.
Example:
SELECT * FROM customers ORDER BY last_name ASC;
This query sorts customers by last name in ascending order.
6. Managing Large Datasets with LIMIT & OFFSET
The LIMIT clause restricts the number of rows returned, while OFFSET skips rows.
Example:
SELECT * FROM products LIMIT 10 OFFSET 20;
This query retrieves 10 products starting from the 21st record.
7. Using Subqueries for Advanced Analysis
A subquery is a query within another query.
Example:
SELECT name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
This query retrieves employees earning more than the average salary.
8. Implementing Conditional Logic with CASE Statement
The CASE statement allows conditional logic in SQL queries.
Example:
SELECT name, CASE WHEN salary > 70000 THEN 'High' WHEN salary BETWEEN 40000 AND 70000 THEN 'Medium' ELSE 'Low' END AS salary_category FROM employees;
This query categorizes employees based on their salary range.
9. Merging Data with UNION & UNION ALL
UNION combines results from multiple SELECT statements and removes duplicates, while UNION ALL retains duplicates.
Example:
SELECT name FROM employees UNION SELECT name FROM managers;
This query retrieves a list of unique names from both employees and managers.
10. Advanced Aggregation & Ranking with Window Functions
Window functions allow calculations across a set of table rows related to the current row.
Example:
SELECT name, department, salary, RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS salary_rank FROM employees;
This query ranks employees within each department based on their salary
0 notes
Text
Understanding Subqueries in T-SQL Programming Language
Subqueries in T-SQL: Understanding Nested Queries with Examples in SQL Server Hello, fellow SQL enthusiasts! In this blog post, I will introduce you to Subqueries in T-SQL – one of the most important and useful concepts in T-SQL: Subqueries. A subquery is a query nested inside another query that helps retrieve data dynamically based on specific conditions. Subqueries can be used in SELECT,…
0 notes
Text
Projects Centered on Machine Learning Tailored for Individuals Possessing Intermediate Skills.

Introduction:
Datasets for Machine Learning Projects , which underscores the importance of high-quality datasets for developing accurate and dependable models. Regardless of whether the focus is on computer vision, natural language processing, or predictive analytics, the selection of an appropriate dataset can greatly influence the success of a project. This article will examine various sources and categories of datasets that are frequently utilized in ML initiatives.
The Significance of Datasets in Machine Learning
Datasets form the cornerstone of any machine learning model. The effectiveness of a model in generalizing to new data is contingent upon the quality, size, and diversity of the dataset. When selecting a dataset, several critical factors should be taken into account:
Relevance: The dataset must correspond to the specific problem being addressed.
Size: Generally, larger datasets contribute to enhanced model performance.
Cleanliness: Datasets should be devoid of errors and missing information.
Balanced Representation: Mitigating bias is essential for ensuring equitable model predictions.
There are various categories of datasets utilized in machine learning.
Datasets can be classified into various types based on their applications:
Structured Datasets: These consist of systematically organized data presented in tabular formats (e.g., CSV files, SQL databases).
Unstructured Datasets: This category includes images, audio, video, and text data that necessitate further processing.
Labeled Datasets: Each data point is accompanied by a label, making them suitable for supervised learning applications.
Unlabeled Datasets: These datasets lack labels and are often employed in unsupervised learning tasks such as clustering.
Synthetic Datasets: These are artificially created datasets that mimic real-world conditions.
Categories of Datasets in Machine Learning
Machine learning datasets can be classified into various types based on their characteristics and applications:
1. Structured and Unstructured Datasets
Structured Data: Arranged in organized formats such as CSV files, SQL databases, and spreadsheets.
Unstructured Data: Comprises text, images, videos, and audio that do not conform to a specific format.
2. Supervised and Unsupervised Datasets
Supervised Learning Datasets: Consist of labeled data utilized for tasks involving classification and regression.
Unsupervised Learning Datasets: Comprise unlabeled data employed for clustering and anomaly detection.
Semi-supervised Learning Datasets: Combine both labeled and unlabeled data.
3. Small and Large Datasets
Small Datasets: Suitable for prototyping and preliminary experiments.
Large Datasets: Extensive datasets that necessitate considerable computational resources.
Popular Sources for Machine Learning Datasets

1. Google Dataset Search
Google Dataset Search facilitates the discovery of publicly accessible datasets sourced from a variety of entities, including research institutions and governmental organizations.
2. AWS Open Data Registry
AWS Open Data provides access to extensive datasets, which are particularly advantageous for machine learning projects conducted in cloud environments.
3. Image and Video Datasets
ImageNet (for image classification and object recognition)
COCO (Common Objects in Context) (for object detection and segmentation)
Open Images Dataset (a varied collection of labeled images)
4. NLP Datasets
Wikipedia Dumps (a text corpus suitable for NLP applications)
Stanford Sentiment Treebank (for sentiment analysis)
SQuAD (Stanford Question Answering Dataset) (designed for question-answering systems)
5. Time-Series and Finance Datasets
Yahoo Finance (providing stock market information)
Quandl (offering economic and financial datasets)
Google Trends (tracking public interest over time)
6. Healthcare and Medical Datasets
MIMIC-III (data related to critical care)
NIH Chest X-rays (a dataset for medical imaging)
PhysioNet (offering physiological and clinical data).
Guidelines for Selecting an Appropriate Dataset
Comprehend Your Problem Statement: Determine if your requirements call for structured or unstructured data.
Verify Licensing and Usage Permissions: Confirm that the dataset is permissible for your intended application.
Prepare and Clean the Data: Data from real-world sources typically necessitates cleaning and transformation prior to model training.
Consider Data Augmentation: In scenarios with limited data, augmenting the dataset can improve model performance.
Conclusion
Choosing the appropriate dataset is vital for the success of any machine learning initiative. With a plethora of freely accessible datasets, both developers and researchers can create robust AI models across various fields. Regardless of your experience level, the essential factor is to select a dataset that aligns with your project objectives while maintaining quality and fairness.
Are you in search of datasets to enhance your machine learning project? Explore Globose Technology Solutions for a selection of curated AI datasets tailored to your requirements!
0 notes